Founds some documentation from the old VRANNIS project we worked on back in Spring of 1999. VRANNIS is a voice recognition system that works via prototyping users.
VRANNIS
Voice Recognition
Artificial Neural Network
Identification System (VRANNIS)
Â
Prepared for:
Dr. Michael Stiber
CSSIE-490, Neural Networks
U of Washington, Bothell
Â
Submitted by:
Â
Â
Botello, Drake R.
dbotello@u.washington.edu
Nguyen, Hoai P.
nguyener@u.washington.edu
Khoat, Do V.
Kdo@u.washington.edu
Graupmann, Timothy A.
tgraupma@u.washington.edu
Â
August 20, 1998
The Voice Recognition Artificial Neural Network (VRANNIS) presented herein is a “speaker identification” Artificial Neural Network (ANN). As such, VRANNIS®
should not be confused with “word recognition” neural networks, which are inherently far more complex and capable of commercial applications.
VRANNIS outputs the personal identity of a speaker’s voice provided that the speaker’s input vector is a member of the prototype vector population. Classification is achieved by comparing the “power spectrum” signature points belonging to the input vector, against the “power spectrum” signature points belonging to the prototype vector population. In these regards, VRANNIS functions as an artificially intelligent human ear. Capable of accurately identifying voices that it is associatively familiar with. Additional time and work would extend the functionality of VRANNIS to encompass reliable identification of non-prototype users.
VRANNIS utilizes a Pentium®
, IBM®
compatible PC, an external microphone and Visual C++®
/MATLAB®
programming tools. The neural network consists of a single perceptron. VRANNIS can classify its four prototype vectors with the following accuracy PV1=100%, PV2=76%, PV3=83% and PV4=100%.
Application Area
Automatic Speech Recognition (ASR) can be broken into three categories: speaker-dependent, speaker-independent and speaker-adaptive. VRAAN is emblematic of a speaker-dependent ASR, as it is trained to recognize one of four specific speakers. As such, VRANNIS has limited commercial appeal beyond that of a toy.
However, achieving consistent and accurate results with in the scope of VRANNIS’s application required a relatively high level understanding of human speech characteristics, signal processing and analysis techniques, principal component analysis, Visual C++®
and MATLAB®
programming ability and neural network architecture knowledge inter alia.
The goal or problem space of VRANNIS entailed developing a neural network to mimic the functionality of the human ear; and approximate the performance of the human ear in regards to reliably identifying the owner of a voice. A human ear can easily identify a familiar or unfamiliar voice by the process of auditory association; which in essence is a biological ASR neural network. The human ear is also capable of reliably identifying a given speaker’s voice in “delta” situations including: rates of speech, manner of speech and background noise. VRANNIS’s accuracy suffers under similar situations.
Â
User Examples, Exercises and Functionality
VRANNIS program files, located in the accompanying diskette, must first be unzipped and loaded into a “temporary VRANNIS program directory” in MATLAB®
– before proceeding with any of the user examples or exercises. The authors highly recommend scanning the diskette with an anti-virus program utility capable of scanning “unopened” .zip files.
A user can demonstrate VRANNIS’s functionality and efficiency in one of three ways:
- For convenience, VRANNIS offers a built in user presentation located within its program file library. The intention of the presentation is to familiarize the user with most of the significant aspects of VRANNIS functionality and accuracy. The developers of VRANNIS suggest viewing this presentation before attempting to conduct user demonstrations number 2, or number 3 below. To view the presentation follow the instructions below, keeping in mind that commands are case sensitive:
- A user can retrieve and load any one of 116 stored prototype .wav’ files to test the functionality and classification accuracy of VRANNIS. Each of the files are numbered and named. For example, (load_sample (‘tim1.wav’)) refers to an individual prototype vector that belongs to Tim Graupmann. Twenty-nine individual voice files, numbered 1:29, exist separately for ‘tim, ‘drake, ‘hoai and ‘khoat. To achieve this aim follow the instructions below:
- A user can connect an external microphone to a PC, or use the PC’s built in microphone (if it has one). The user would pronounce “Hello computer” twenty-nine times, and store each utterance as one of the named protoype vectors in VRANNIS. Bear in the mind that the user has 8001 milliseconds to complete the utterance. Following, VRANNIS will identify the user’s voiceprint sample as a member of the prototype population. To achieve this goal follow the instructions below:
a. EDU>> present
b. Strike any key to scroll forward through the entire presentation
a. variable=load_sample(‘drake1.wav’);
b. Substitute ‘drake(1:29).wav’ to load additional ‘drake prototype vectors
c. Substitute ‘(hoai, khoat, or tim)1.wav’ to load additional member prototype vectors
- gsave_sample(‘drake1.wav’);
- Traverse 1 through 29 repeating the words, “hello computer”
- Be sure to use the name drake, hoai, khoat, or tim for all prototype samples
Â
VRANNIS Signal Processing and Design Criteria
Initial Signal Processing
A voiceprint was digitally recorded twenty-nine individual times for each of the four individuals belonging to the prototype population (P11:29Â…P41:29). Subsequently, each voiceprint was converted from amplitude over time – to power (p) over frequency by application of the Fourier Transform.
Following, the power spectrum (total number of p-values) belonging to P11:29Â…P41:29 was reduced from 4,000 p-values to 500 p-values, by application of the fft function (See Figure 1, page 9).
Signal processing achieved three (3) important VRANNIS milestones as follows:
- The digital voice signal was successfully converted from an amplitude domain to a power spectrum domain, hereafter referred to as the p-spectrum.
- The total number of p-values in the p-spectrum was reduced from 4,000 to 500, which produced notably improved wave pattern features, as illustrated in Figure 1.
- P11:29Â…P41:29 voiceprint samples, each spanning a p-spectrum of 500 individually indexed p-values, became “principal” prototype voiceprints.
Principal Signal Component Processing
Principal voiceprints P11:29Â…P41:29 varied dramatically from one another – as one would expect. Unexpectedly, the individual voiceprints belonging to P11:29, P21:29, P31:29, and P41:29 also varied substantially amongst themselves. Thus the p-values in each of 1:29 voiceprints belonging to P1Â…P4 required “normalization” before being construction into reliable prototype vectors for (PV1Â…PV4) – representative of each 1:29 voice prints belonging to P1Â…P4.
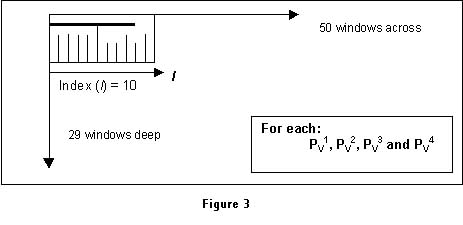
Normalization was achieved by dividing each p-spectrum spanning 500 p-values for PV1Â…PV4 into fifty discrete sampling windows. Each sampling window contains ten individually indexed p-values. A hypothetical sampling window is shown in Figure 2 below, containing ten indexed p-values:

Â
Algorithms search each sampling window (50×29) belonging to each voiceprint for P1, P2, P3 and P4 and returns three different values for each sampling window. The mean of each p-value, the mode of the maximum p-value and then calculates the mean of the (mode + the maximum indexed p-value).
Referring to Figure 3, The mean represents the values of all ten p-values shown as vertical lines. The vertical line intersecting the bold horizontal line represents the mode of the maximum indexed p-value. Thus the mode of the max indexed p-value is identified, the mean of the max indexed p-value is computed to a single value; and the mean of the mode and the mean is computed as the final value for a single sampling window. The equation is written as:
mean{max(p-value index), mode(max(p-value index))}. (4.0)
Principal signal component processing achieved two (2) additional design milestones as follows:
- The 29 individual voice waves belonging to P1, P2, P3 and P4 were each compiled to one principal indexed vector voiceprint (50X1) referred to as: PV1, PV2, PV3 and PV4. Note that the single vector voiceprint(s) is a function of the significant p-spectrum properties formerly contained in all 29-voiceprints belonging to P1, P2, P3 and P4.
- The fifty resulting indexed p-values for each of PV1Â…PV4 represent highly reliable data to train VRANNIS (for PV1, PV2, PV3 and PV4).
Â
Interim Vector Component Processing
As an input vector passes through each of the signal processing stages discussed above it’s p-indexed wave form navigates through each of the indexed p-values belonging to PV1, PV2, PV3 and PV4. This dynamic relationship is illustrated in Figure 4, page 10.
Following, an algorithm measures the distance from each indexed p-value belonging to the input vector to each of the indexed p-values belonging to PV1, PV2, PV3 and PV4 . The algorithm returns the prototype vector (PV1, PV2, PV3 or PV4) that is closest in distance to the input vector at each of the fifty p-indexed sampling windows (note that the absolute value compensates for negative distances). In these regards, this vector component processing methodology borrows (partially) from the “distance logic” found in Hamming neural networks.
The algorithm counts the number of occurrences (or hits) that are coincident with the input vector and PV1, PV2, PV3 or PV4. A hit is regarded as a 1 where as a miss is regarded as a -1, which gives rise to four vectors each containing fifty elements. This information is input into a single layer perceptron for final classification.
Â

Â
VRANNIS Test Results
Â
|
NAME |
Drake 1:29 |
Hoai 1:29 |
Khoat 1:29 — 3 |
Tim 1:29 |
|
ACCURACY |
100% |
76% |
83% |
100% |
Alternative Approaches
VRANNIS could be implemented using a Hamming neural network, which would conceivably make VRANNIS substantially more powerful. Particularly for identifying both prototype and non prototype users. The addition of low pass filter is viewed as secondary to furthering the accuracy of a Hamming neural network. That is, we would first like to develop a Hamming network and test the results before implementing filtering techniques.
Â
Limitations
VRANNIS suffers from the inability to identify non-prototype users as noted above. In addition, VRANNIS’s classification reliability suffers variably if the sampling session:
- Is not conducted in exactly the same room with the same microphone.
- Is conducted in the same room, but with a different microphone.
- Is conducted in a different room, but with the same microphone.
We have not isolated the cause and affect from the foregoing variable circumstances.
If afforded additional time, we believe that energies devoted to replacing VRANNIS’s architecture with a Hamming neural network would most likely eliminate or mitigate the apparent “sensitivities” associated with the current version of VRANNIS.
Â
Problems Encountered
As laypersons, new to neural networks and voice signal processing, we encountered several challenges both individually and collectively. However, we regard these instances as applied learning opportunities – which is why we elected to develop a project rather than write a research paper. The new skills and awareness we have “earned” encompasses abilities that we did not fully possess before embarking.
Setting philosophical meandering aside we faced the following problems:
- We were unable to successfully implement the recurrent layer in the Hamming Network, despite very promising results in the feed-forward layer. Never the less, the code still exists in a VRANNIS directory. Following a half-day of unsuccessful attempts, we were left with little time to fully investigate this failing.
- We were unable to employ supervised learning to establish the proper weight matrix and bias values for a perceptron. The dimensions of VRANNIS’s four prototype vectors are 50X4. Starting with arbitrary values, MATLAB did not arrive at the proper values following 3,000 iterations. We do not know if a solution simply doesn’t exist, or additional iterations were necessary.
Thus we employed matrix and bias values that returned any of the four prototype vectors. However, we had to develop a technique to calculate the distances from the input vector and the four prototype vectors in such a way that -1 or 1 would be returned. The “distance technique” we employed approximates the logic of Hamming, which is one of the reasons we “believe” a Hamming network is ideal for VRANNIS.
- We found it very difficult to find research information suited for novices, who were conducting their first attempt with voice related ANN’s. In this regard we are grateful for the mentoring we received from Dr. Stiber and Dr. Jackels; and the precious few pages of information we found in books – listed under references.
- Communications between group members was challenging and hilarious. It is difficult for Hoai and Khoat to understand many American colloquialisms. Similarly, Tim and Drake had difficulty understanding Vietnamese influenced rates of speech and pronunciations.
Curiously, VRANNIS had little difficulty identifying the voice of anyone of us!
With respect to the “problems” listed herein, a few of us would like to meet with you late next week (or the next) to discuss any insights you may wish to share.
Â
Future Work
While we seemingly have placed the Hamming Net on a pedestal, there are several avenues within the context of VRANNIS, as it presently exists, that seem worthy of investigating. For example:
- Increase the number of recorded wave files belonging to each prototype member from 29 to 50. Then 50 to 100. Compare test results each time. No changes would be made to the total p-value spectrum of 500 per prototype member.
- Change the total p-value spectrum from 500 to 750; and increase the number of indexed sampling windows from 50 to 150. Compare test results. No changes would be made to the total number of recorded wave files belonging to each prototype member (1:29).
- Change the input voice wave “hello computer” to a single syllable word; and make the changes, in stages followed by testing, suggested above.
In essence, we would first attempt to discover if the accuracy of VRANNIS could be improved for externally voiced utterances – by simply increasing the number of recorded voice wave samples. Secondarily, we would increase the p-spectrum field. Finally, we would greatly increase the number of indexed p-value sampling windows.
All test results would be recorded, analyzed and documented. In this regard, “future work” constitutes a “research project” that Tim Graupman, Drake Botello and possibly others would be willing to undertake in the future. Either personally, or under a directed study.
Having completed all of the proposed research, we would next focus our efforts on developing a Hamming Neural Network for VRANNIS. Test results would be compared to each of the other successive methodologies.
Â
Â
Â
Â
Â
Â
Â
Â
Â
Â
References
Â
Â
Hagen, Martin T., and Howard B. Demuth, and Mark Beale, Neural Network Design (Boston, MA: PWS Publishing Company, 1996). 3.12-3.13, 4.13-4.20, 11.1-11.23
Â
Hanselman, Duane, and Bruce Littlefield, The Student Edition of MATLAB, Version 5 User’s Guide (Upper Saddle River, NJ: Prentece-Hall, Inc., 1997). n.p
Â
Hanselman, Duane, and Bruce Littlefield, The Student Edition of MATLAB, Version 5 User’s Guide, Online. Internet. Available: http://www2.rrz.une/themen/cmp.cal-tech.edu/matlab
, n.p. 10 July 1998.
Â
Looney, Carl G., Pattern Recognition Using Neural Networks: Theory and Algorithms for Engineers and Scientists (New York, NY: Oxford Press Inc., 1997). 80-81, 434-439.
Â
Carpenter, Gail A., and Stephen Grossberg, Pattern Recognition by Self-Organizing Neural Networks: (Cambridge, MA and London, England: The MIT Press 1991). 458.
Danset, Paul T., Speech Recognition Using Neural Networks: Master’s Thesis (Seattle, WA: University of Washington., 1993). 4.
Lea, et al, Trends in Speech Recognition (Englewood Cliffs, NJ: Prentice-Hall Inc., 1980). 10, 40-43, 108.
Dowla, Farid U, and Leah L. Rogers, Solving Problems in Environmental Engineering and Geosciences (Cambridge, MA: The MIT Press 1991). 104.
Â
Â
Â
Â
Â
Â
Â
Â
Appendix
Â
VRANNIS test resultsÂ…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…Â…..Page 11-14
Â
Â
Â
Â
Â
Â